Introduction
Enterprises need visibility into how models are making predictions. Mission-critical decisions cannot be made using a black box. Teams need to understand and explain model outputs. One such method is by understanding how each of the input features is impacting the outcome.
ModelOp Center provides a framework for calculating, tracking, and visualizing Model Interpretability metrics. Each of these can be determined on a model-by-model basis. You can also enforce a standard using an MLC Process as needed. The subsequent sections provide more detail on how to use ModelOp Center to implement Interpretability into your ModelOps program.
Interpretability in MOC
While model interpretability is a complex and rapidly-changing subject, ModelOp Center can assist you in understanding how much each feature contributes to the prediction, as well as monitoring each feature’s contribution over time. ModelOp Center does this by expecting a trained SHAP explainer artifact and finding the SHAP values over the input dataset. The SHAP results are persisted for auditability and tracking over time.
In the sections below we will demonstrate how an explainability monitor can be setup in MOC. The example used is based on the German Credit business model, which can be found here. The business model is the base model producing inferences (predictions). The SHAP monitor can be found here. The monitor is itself a storedModel in MOC.
Adding a custom SHAP monitor to a business model
To add the SHAP monitor referenced above to the German Credit (GC) model, follow these steps:
Import the GC model into MOC by Git reference.
Create a snapshot of the GC model. In doing so, it is not necessary to deploy the snapshot to any specific runtime, as we will not be running any code from the GC model itself.
Import the Feature Importance monitor by Git reference.
Create a snapshot of the monitor. You may specify a target runtime on which you’d like the monitoring job to be run.
Associating the monitor to the business model:
Navigate to the GC model spapshot,a nd click on ADD, then on MONITOR.
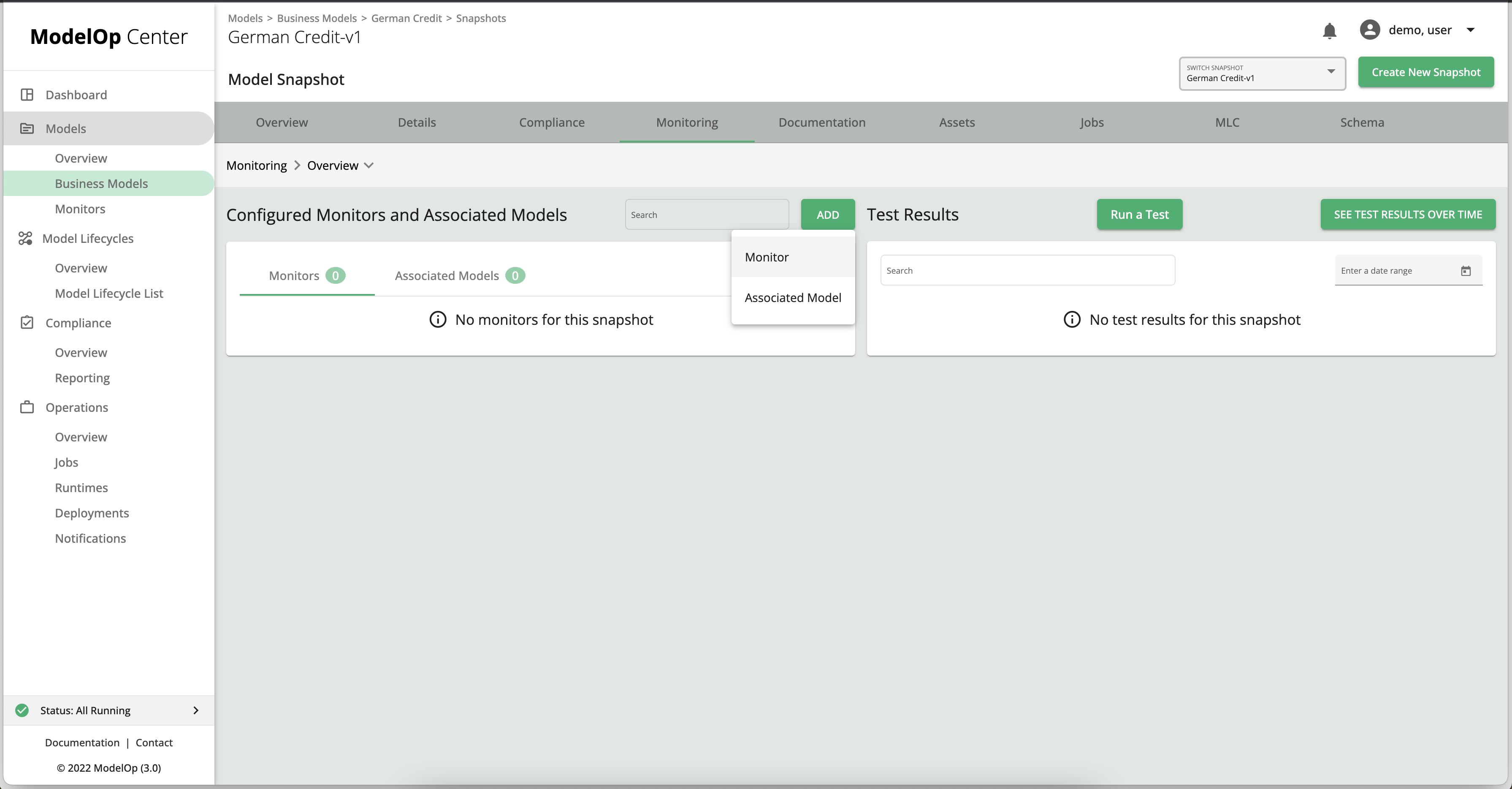
Select the SHAP monitor from the list of monitors, and then select its snapshot.
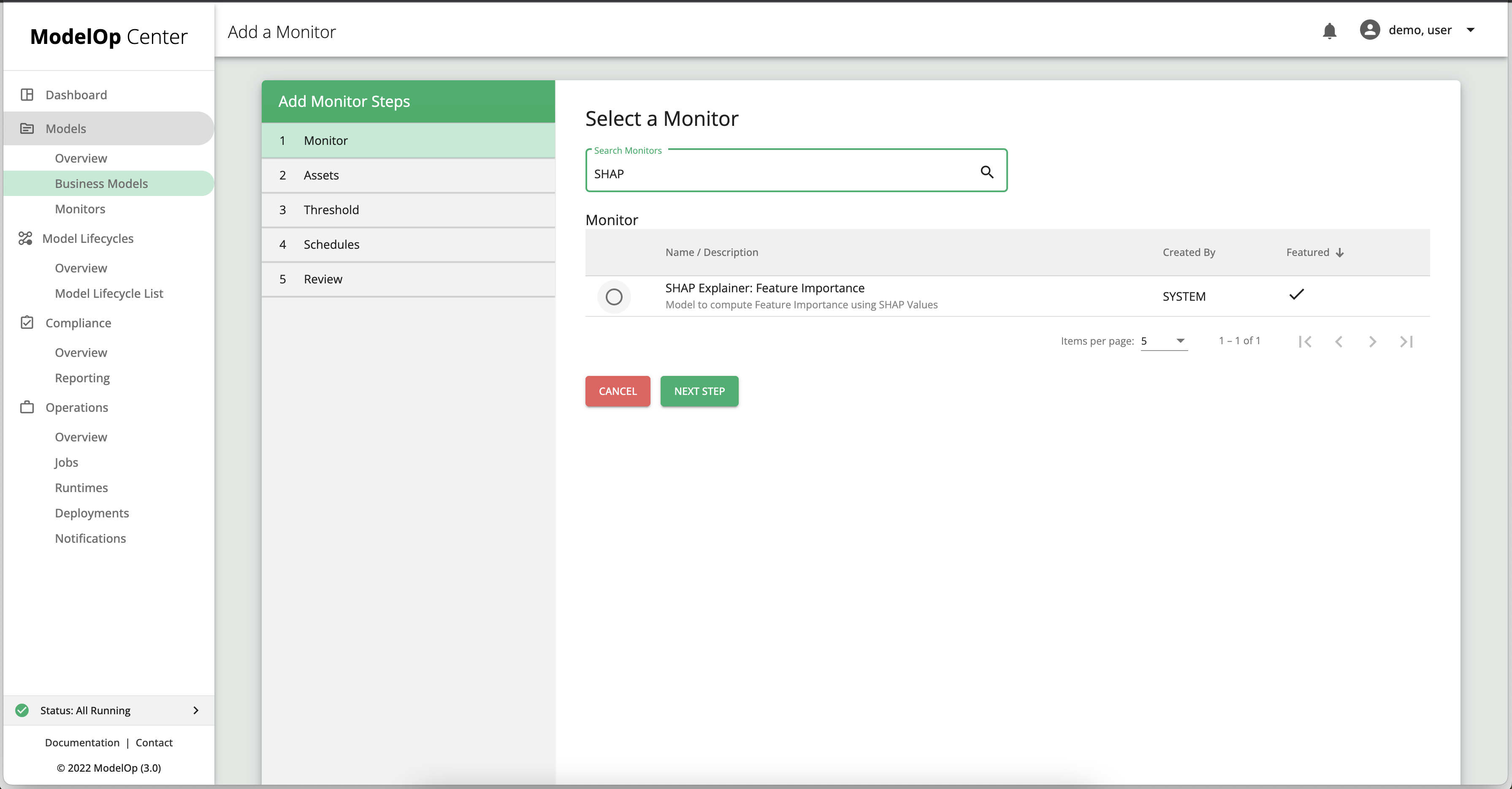
On the Assets page:
Select an input asset from the existing data assets of the GC business model, say, df_sample_scored.json. In a PROD environemnt, you are more likely to add a SQL asset (by connection and query string), or an S3 asset (by URL).
under “Additional Assets”, select the existing assets
shap_explainer.picklefor Pre-trained SHAP explainer, andpredictive_features.picklefor List of predictive features as used by scoring model.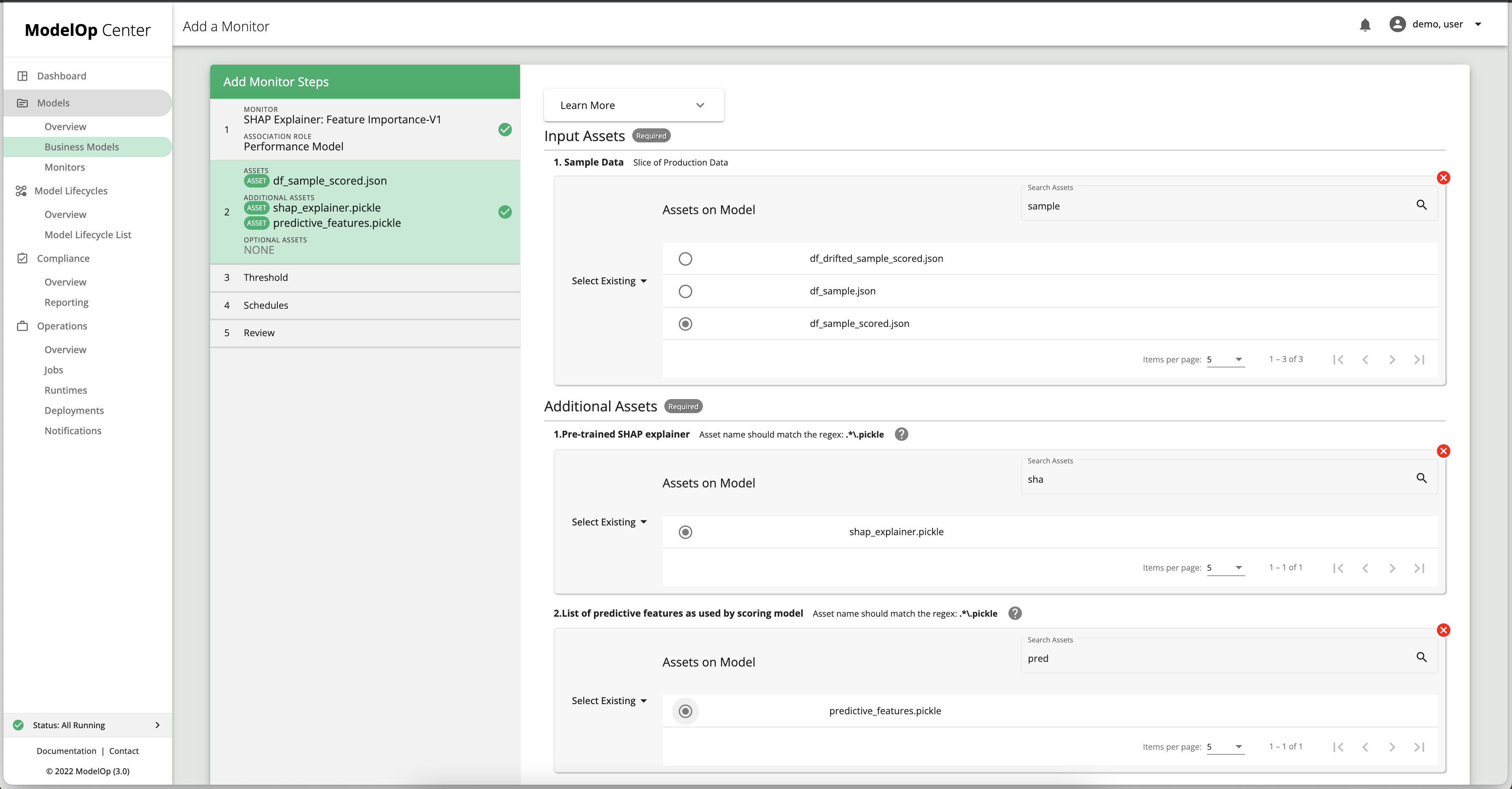
Click Next.
For this example we will skip the Threshold and Schedule steps.
On the last page, click Save.
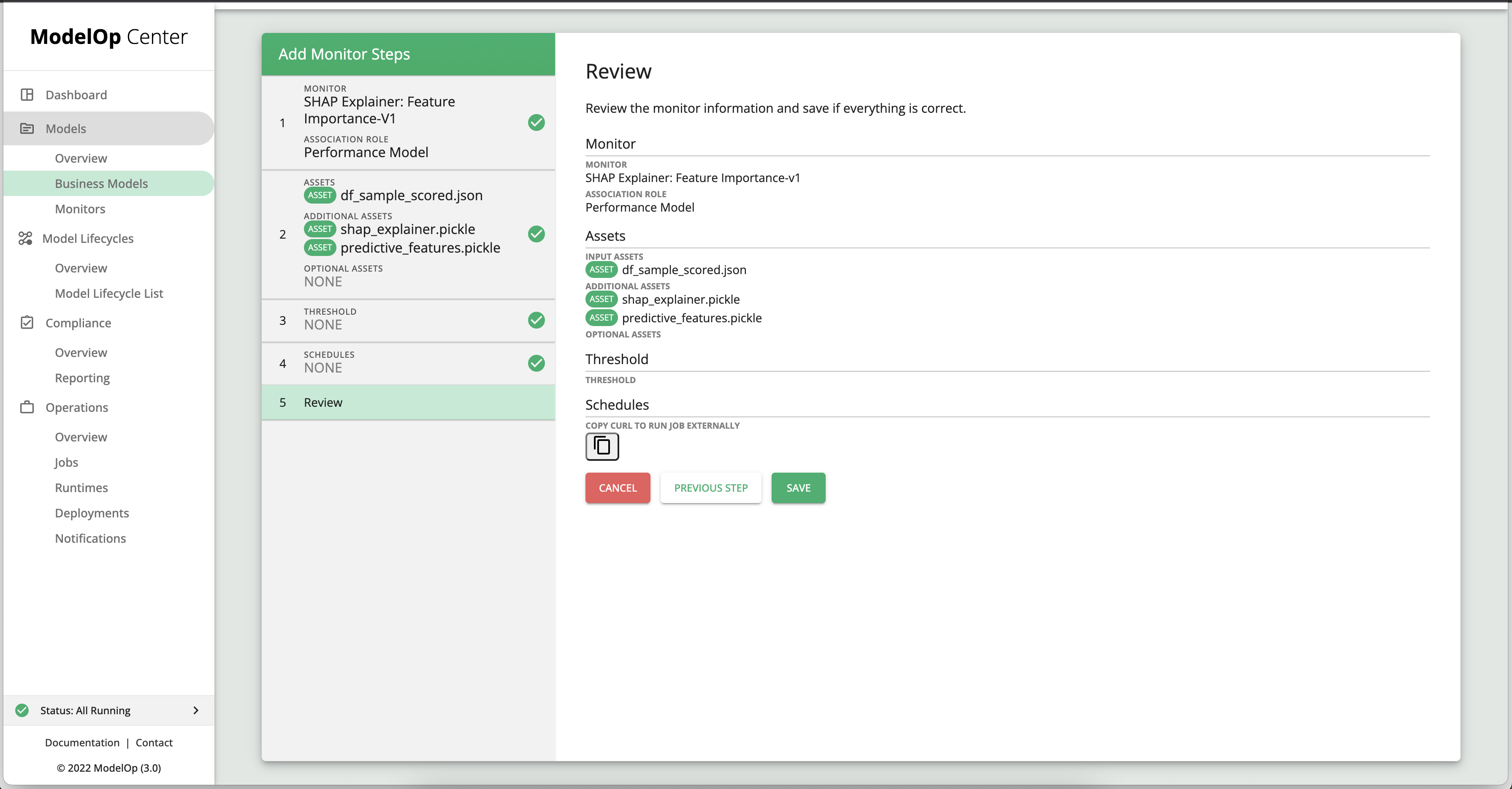
To run the monitor, navigate to the snapshot of the GC model, and then to monitoring.
Under the list of monitors, click the play button next to the SHAP monitor to start a monitoring job. You will then be re-directed to the Jobs page, where you’ll be able to look at live logs from the monitoring run.
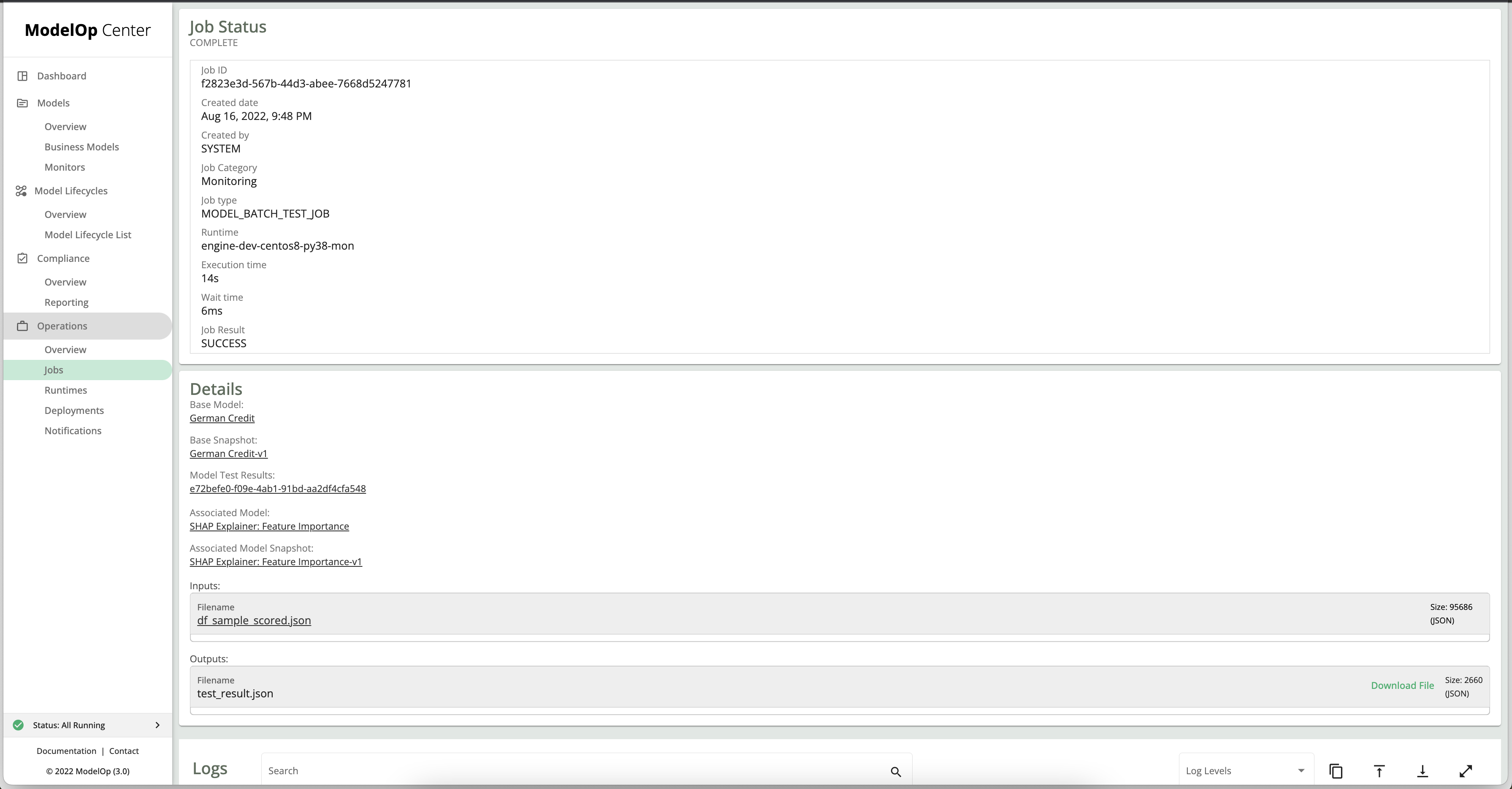
To download the Test results, click on Download File in the Details box. To view a graphical representation of the test result, click on the Model Test results UUID link in the Details box. You will be re-directed to the snapshot’s monitoring page, and presented with the following output:
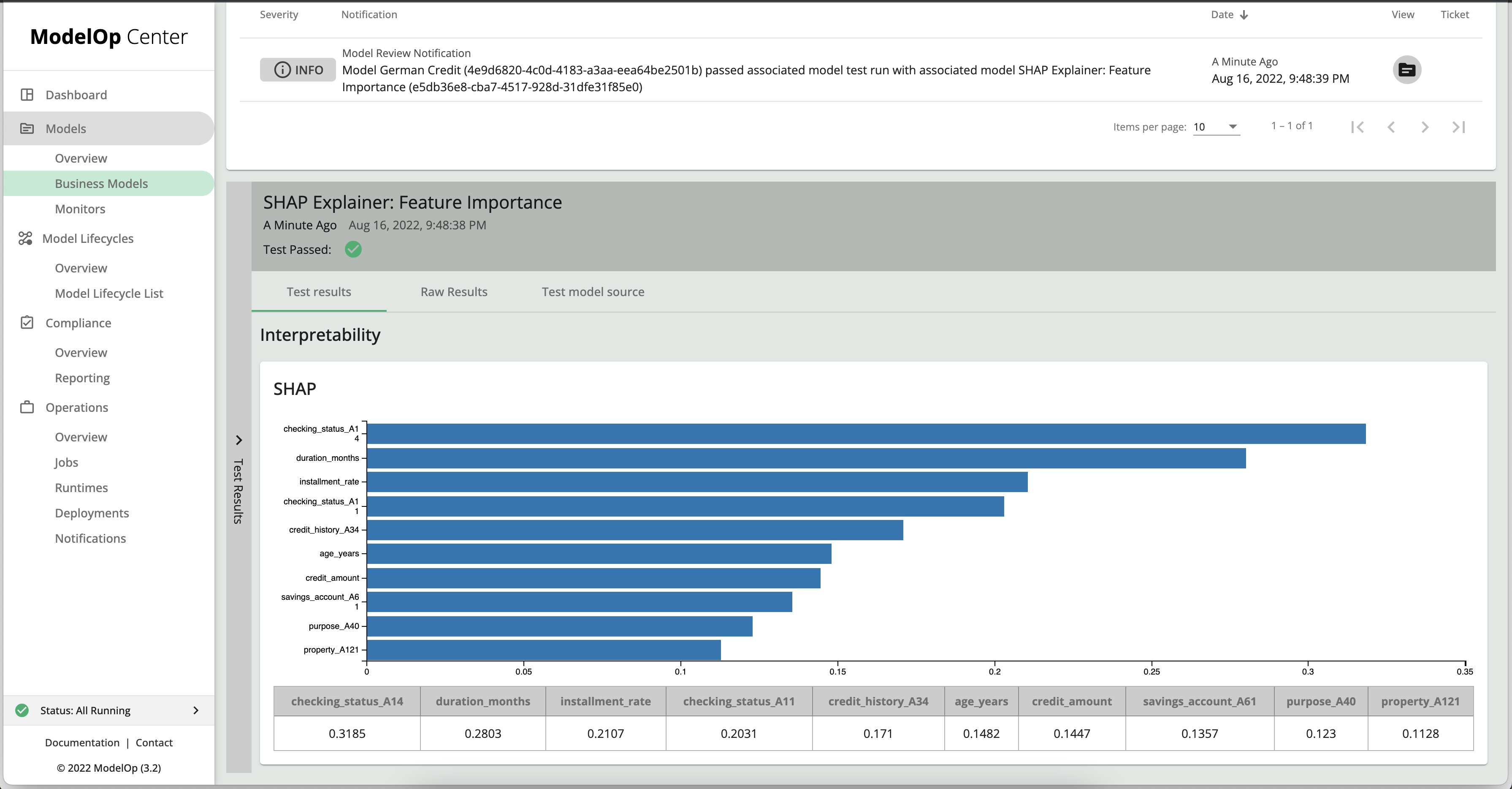
A walkthrough of the custom monitoring code
As mentioned above, the monitor is itself a MOC model, managed and versioned as any other model. The primary source code file, feature_importance_shap.py, contains the metrics function that is run when a monitoring job is started.
| Code Block | ||
|---|---|---|
| ||
import pandas
import numpy
import pickle
import shap
import logging
logger = logging.getLogger(__name__)
logger.setLevel("INFO")
# modelop.init
def begin():
global predictive_features, shap_explainer
# Load pickled predictive feature list
predictive_features = pickle.load(open("predictive_features.pickle", "rb"))
logger.info("predictive_features: %s", predictive_features)
# Load pre-trained SHAP explainer
shap_explainer = pickle.load(open("shap_explainer.pickle", "rb"))
logger.info("shap_explainer loaded!") |
The first section of code shown above contains the python import statements, as well as the init (begin) function, which serves to load into memory the pre-trained SHAP explainer, as well as a list of predictive features. These files are created and saved (pickled) at the model development/validation stage, and are commited as model assets along wioth the business model (German Credit) code.
The MOC runtime first executes the import statements and then the init function. The metrics function, shown below, is the next snipped of code to be run.
| Code Block | ||
|---|---|---|
| ||
# modelop.metrics
def metrics(dataframe: pandas.DataFrame) -> dict:
# Getting dummies for shap values
data_processed = preprocess(dataframe)[predictive_features]
# Returning metrics
return {"interpretability": [compute_feature_importance(data_processed)]} |
The metrics function above call two additional functions:
a preprocessing function (
preprocess) which One-Hot encodes the input data (the input tometrics), according to the list of features unpickled frompredictive_features.pickle:Code Block def preprocess(data: pandas.DataFrame) -> pandas.DataFrame: """Function to One-Hot-Encode input data Args: data (pandas.DataFrame): input data. Returns: pandas.DataFrame: OHE version of input dataframe. """ data_processed = data.copy(deep=True) # One-Hot encode data with pd.get_dummies() data_processed = pandas.get_dummies(data_processed) # In case features don't exist that are needed for the model (possible when dummying) # will create columns of zeros for those features for col in predictive_features: if col not in data_processed.columns: data_processed[col] = numpy.zeros(data_processed.shape[0]) return data_processeda feature-importance computation function (
compute_feature_importance) which computes and sorts feature-importance metrics according to the pre-trained SHAP explainer unpickled fromshap_explainer.pickle:Code Block def compute_feature_importance(data: pandas.DataFrame) -> dict: """A function to compute feature importance using pre-trained SHAP explainer. Args: data (pandas.DataFrame): OHE input data. Returns: dict: SHAP metrics. """ # Getting SHAP values shap_values = shap_explainer.shap_values(data) # Re-organizing and sorting SHAP values shap_values = numpy.mean(abs(shap_values), axis=0).tolist() shap_values = dict(zip(data.columns, shap_values)) sorted_shap_values = { k: v for k, v in sorted(shap_values.items(), key=lambda x: x[1]) } return { "test_name": "SHAP", "test_category": "interpretability", "test_type": "shap", "metric": "feature_importance", "test_id": "interpretability_shap_feature_importance", "values": sorted_shap_values, }
The metrics function returns the results of the feature importance function in JSON-serializable format which can be visualized in the MOC UI.
Next Article: Model Governance: Model Versioning >