Introduction
Enterprises need visibility into how models are making predictions. Mission-critical decisions cannot be made using a black box. Teams need to understand and explain model outputs. One such method is by understanding how each of the input features is impacting the outcome.
ModelOp Center provides a framework for calculating, tracking, and visualizing Model Interpretability metrics. Each of these can be determined on a model-by-model basis. You can also enforce a standard using an MLC Process as needed. The subsequent sections provide more detail on how to use ModelOp Center to implement Interpretability into your ModelOps program.
Interpretability in MOC
While model interpretability is a complex and rapidly-changing subject, ModelOp Center can assist you in understanding how much each feature contributes to the prediction, as well as monitoring each feature’s contribution over time. ModelOp Center does this by expecting a trained SHAP explainer artifact and finding the SHAP values over the input dataset. The SHAP results are persisted for auditability and tracking over time.
The following example uses the SHAP library to calculate the impact of the features on the prediction, calculates the average SHAP value for each feature, then yields it as a dictionary.
| Code Block | ||
|---|---|---|
| ||
import pandas as pd
import numpy as np
import shap
import pickle
from scipy.special import logit
# modelop.init
def begin():
# Load SHAP explainer, model binary, and other parameters into global variables
global explainer, lr_model, threshold, features
model_artifacts = pickle.load(open("model_artifacts.pkl", "rb"))
explainer = model_artifacts['explainer']
lr_model = model_artifacts['lr_model']
threshold = model_artifacts['threshold']
features = model_artifacts['features']
pass
def preprocess(data):
"""
A Function to pre-process input data in preparation for scoring.
Args:
data (pandas.DataFrame): Input data.
Returns:
(pandas.DataFrame): Prepped data.
"""
prep_data = pd.DataFrame(index=data.index)
prep_data["logit_int_rate"] = data.int_rate.apply(logit)
prep_data["log_annual_inc"] = data.annual_inc.apply(np.log)
prep_data["log_credit_age"] = data.credit_age.apply(np.log)
prep_data["log_loan_amnt"] = data.loan_amnt.apply(np.log)
prep_data["rent_indicator"] = data.home_ownership.isin(['RENT']).astype(int)
return prep_data
def prediction(data):
"""
A function to predict on prepped input data, using the loaded model binary.
"""
return lr_model.predict_proba(data.loc[:, features])[:,1]
def get_shap_values(data):
"""
A function to compute and return sorted SHAP values, given the loaded SHAP explainer.
"""
shap_values = explainer.shap_values(data.loc[:, features])
shap_values = np.mean(abs(shap_values), axis=0).tolist()
shap_values = dict(zip(features, shap_values))
sorted_shap_values = {
k: v for k, v in sorted(shap_values.items(), key=lambda x: x[1])
}
return sorted_shap_values
# modelop.metrics
def metrics(data):
metrics = {}
# Prep input data
prep_data = preprocess(data)
data = pd.concat([data, prep_data], axis=1)
# Compute predictions
data.loc[:, 'probabilities'] = prediction(data)
data.loc[:, 'predictions'] = data.probabilities \
.apply(lambda x: threshold > x) \
.astype(int)
# Compute SHAP values
metrics['shap'] = get_shap_values(data)
yield metrics |
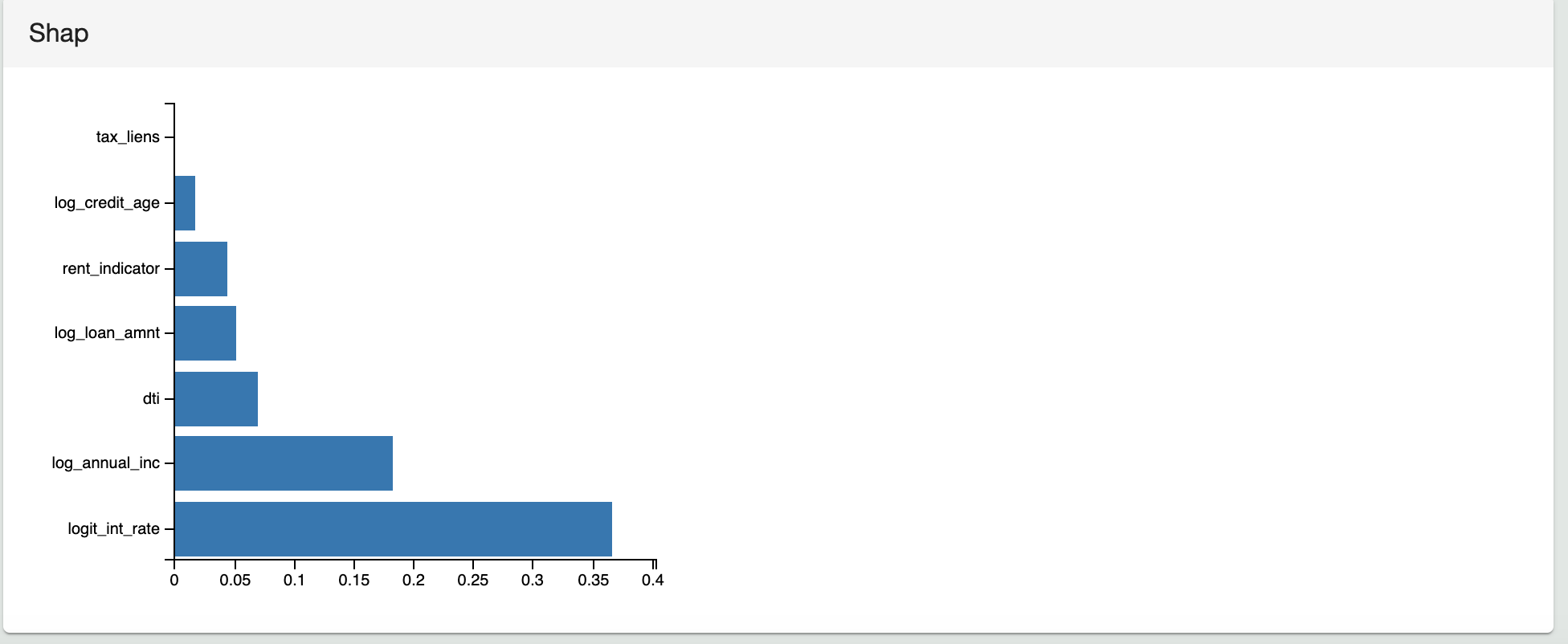
The following image shows the corresponding visualization for the SHAP values of the sample model to the Test Results in ModelOp Center.
Next Article: Model Governance: Model Versioning >