Introduction
Operational performance monitors include:
Runtime Monitoring
Model In-Line Data Integrity Monitoring
Runtime Monitoring
To get real-time insight into how your model is performing, you can click into a detailed, real-time view of the Runtime information for the deployed model. This includes real-time monitors about the infrastructure, data throughput, model logs, and lineage, where available.
To see the Runtime Monitoring, navigate to the deployed model: Runtimes → Runtime Dashboard → <Runtime where your model is deployed>
The Runtime monitor displays the following information about the Runtime environment:
CPU Utilization - User CPU utilization and Kernel CPU usage
System Resource Usage - real-time memory usage
Lineage of the deployment - MLC Process metadata that details the deployment information and history
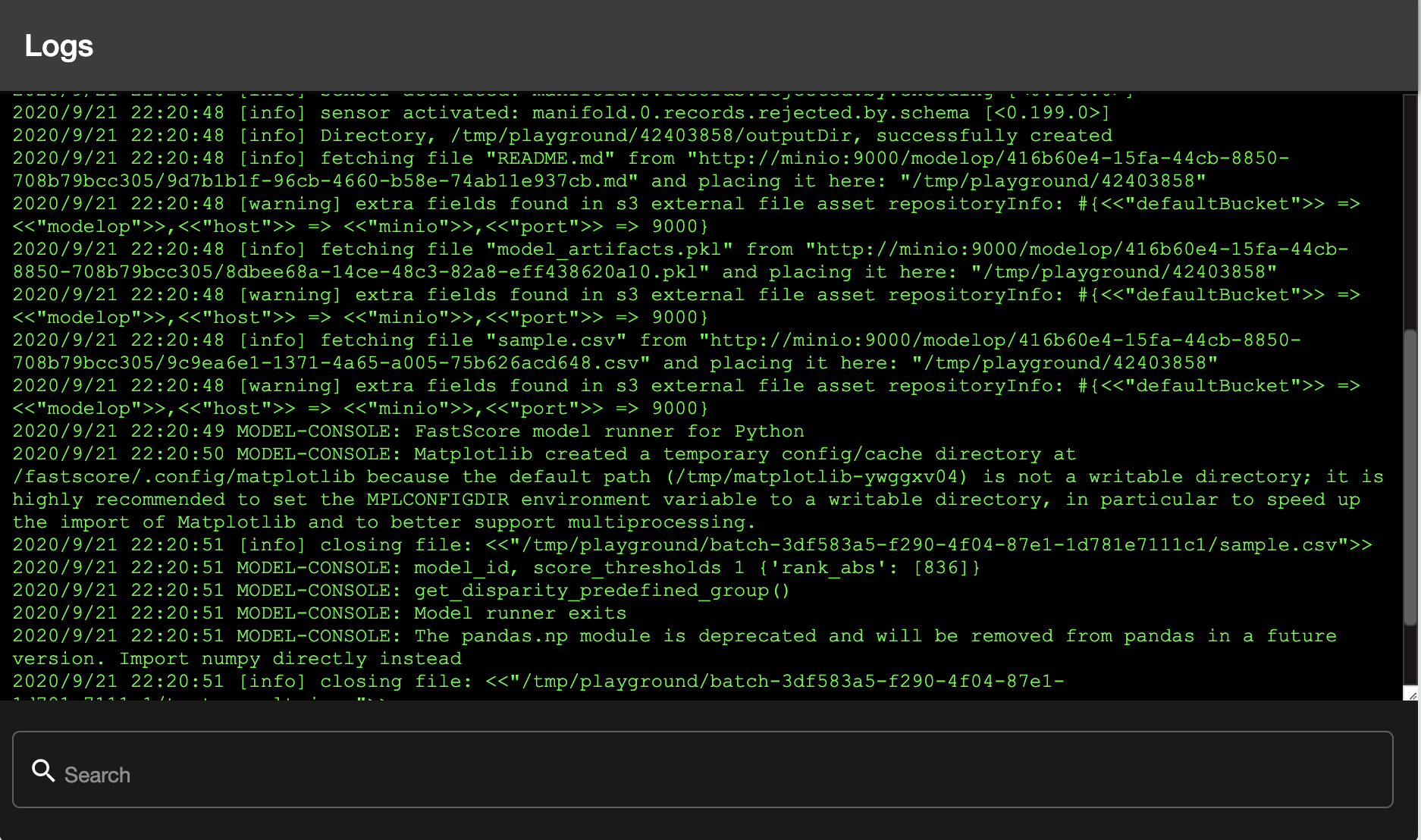
Logs - A live scroll of the model logs

Model Data Monitoring
While not required, ModelOp Center provides its own runtime out of the box, which has the capability to validate incoming and outgoing data from the model for adherence to a defined schema. This schema is a defined structure that the model expects to ensure that erroneous data is not accidentally processed by the model causing model stability errors or downtime.
Overview
ModelOp Center enforces strict typing of engine inputs and outputs at two levels: stream input/output, and model input/output. Types are declared using AVRO schema.To support this functionality, ModelOp Center’s Model-Manage maintains a database of named AVRO schemas. Python and R models must then reference their input and output schemas using smart comments. (PrettyPFA and PFA models instead explicitly include their AVRO types as part of the model format.) Stream descriptors may either reference a named schema from Model Manage, or they may explicitly declare schemas.
In either case, ModelOp Center performs the following type checks:
Before starting a job: the input stream’s is checked for compatibility against the model’s input schema, and the output stream’s schema is checked for compatibility against the model’s output schema.
When incoming data is received: the incoming data is checked against the input schemas of the stream and modelschema.
When an output is produced by the model: , the outcoming emitted data is checked against the model and stream’s output schemas.
schema.
Input or output records that are rejected due to schema incompatibility appear as messages in the ModelOp runtime logs.
Examples
The following model takes in a record with three fields (name, x, and y), and returns the product of the two numbers.
| Code Block | ||
|---|---|---|
| ||
# modelop.schema.0: input_schema.avsc
# modelop.schema.1: output_schema.avsc
def action(datum):
my_name = datum['name']
x = datum['x']
y = datum['y']
yield {'name': my_name, 'product':x*y}
|
The corresponding input and output AVRO schema are:
| Code Block | ||
|---|---|---|
| ||
{
"type":"record",
"name":"input",
"fields": [
{"name":"name", "type":"string"},
{"name":"x", "type":"double"},
{"name":"y", "type":"double"}
]
} |
and
| Code Block | ||
|---|---|---|
| ||
{
"type":"record",
"name":"output",
"fields": [
{"name":"name", "type":"string"},
{"name":"product", "type":"double"}
]
} |
So, for example, this model may take as input the JSON record
| Code Block |
|---|
{"name":"Bob", "x":4.0, "y":1.5} |
and score this record to produce
| Code Block |
|---|
{"name":"Bob", "product":"6.0"} |
Note that in both the model’s smart comments, the CLI commands, and the stream descriptor schema references, the schemas are referenced by their name in model manage, not the filename or any other property.
Next Article: Drift Monitoring >